Large Scale ETL Pipeline
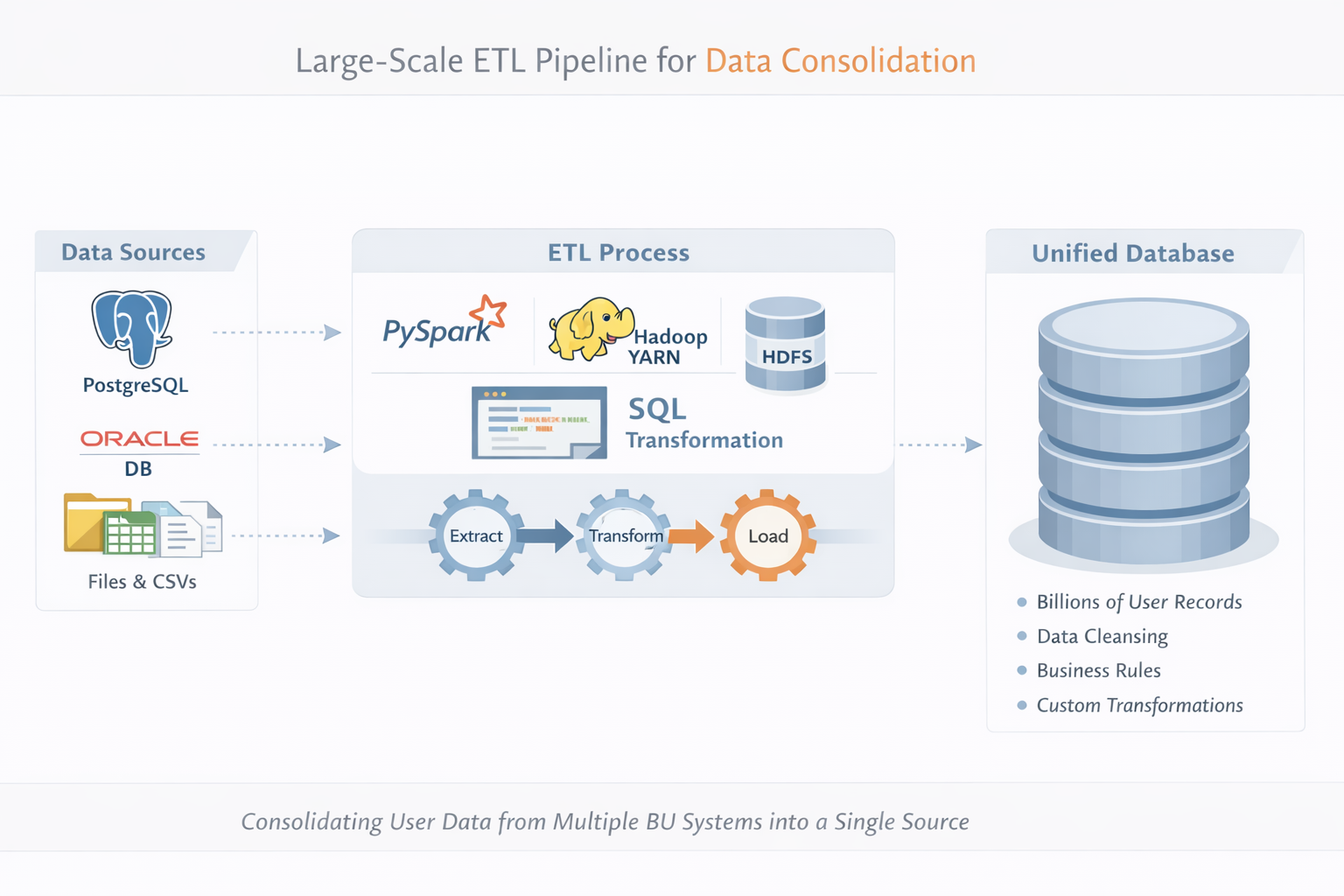
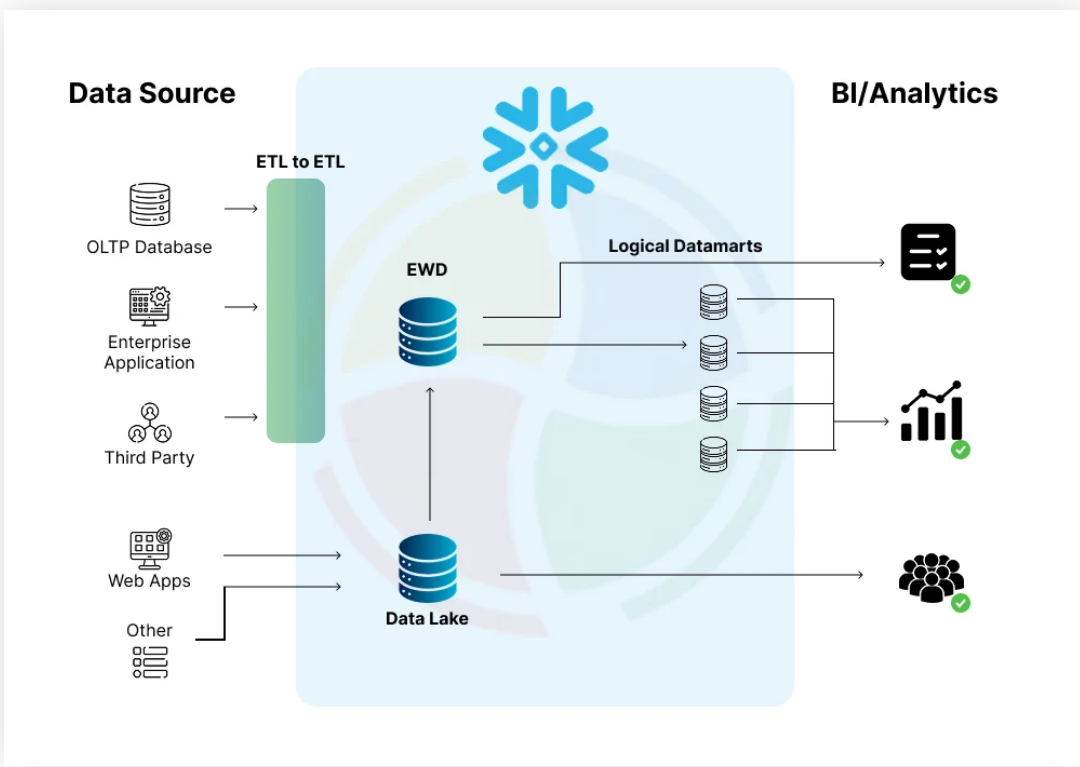
Consolidate billions of user records from multiple Business Unit (BU) source systems into a single unified data platform, applying large-scale business-driven transformations while meeting high performance, scalability, and production reliability requirements.
Summary
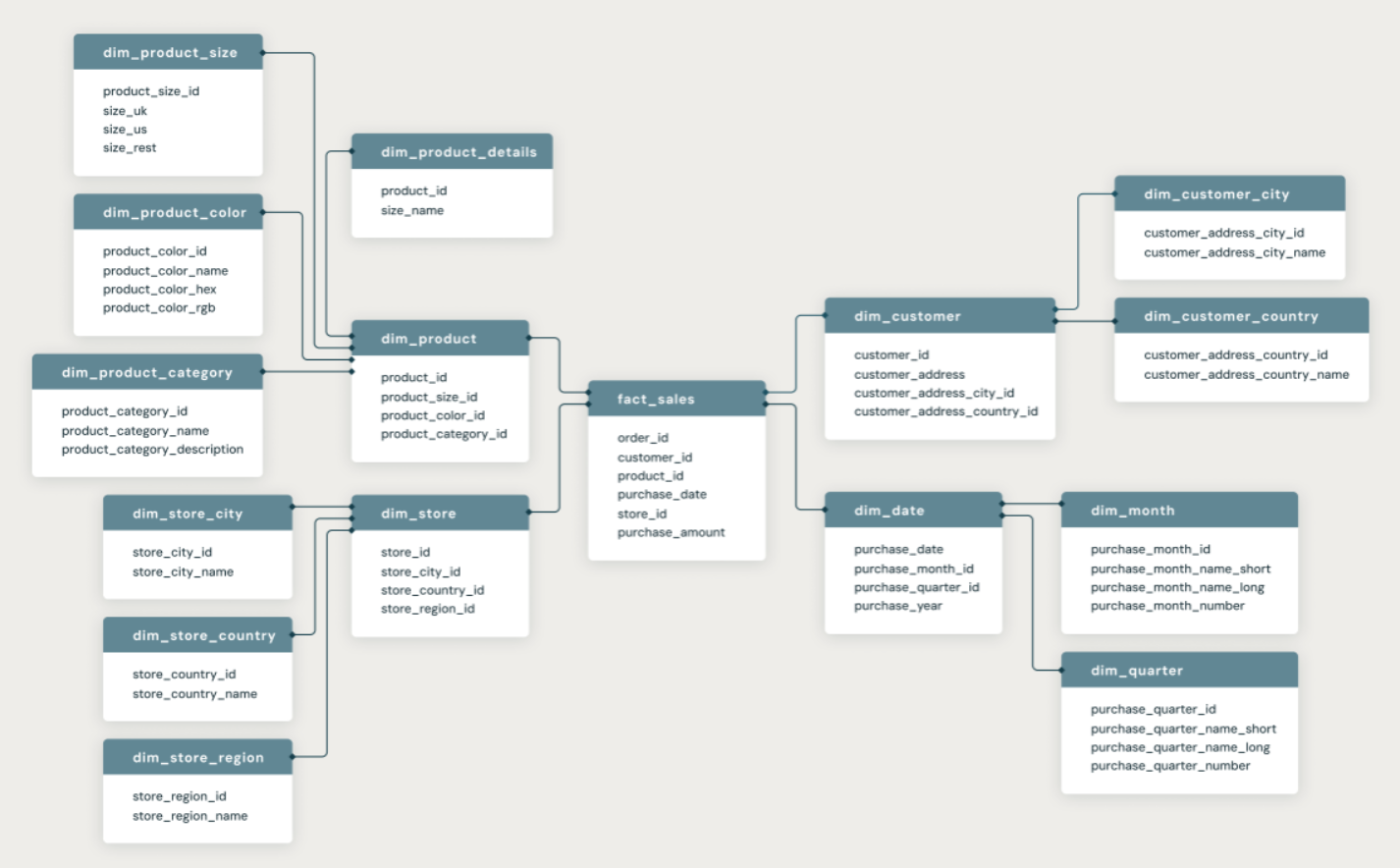
Designed and implemented large-scale ETL pipelines using PySpark to consolidate 5–10+ billion user records from multiple sources into a unified data store. Developed config-driven frameworks for reusable execution across production pipelines with complex SQL transformations for business rules and data cleansing. Optimized performance using partitioning and bucketing strategies, reducing data shuffle and improving load times by 30–50% on large datasets. Orchestrated production workflows using AutoSys with automated scheduling, retries, and failure notifications for high reliability.